tRPC
tRPC est un système facilitant l’implémentation de la communication entre un client et un serveur, par exemple entre un frontend et un backend d’une application web. Le concept de RPC, Remote Procedure Call, consiste à appeler les procédures d’un serveur distant depuis un client de manière transparente, c’est à dire que la communication réseau sous-jacente est abstraite par ce système. tRPC garantit la sécurisation du typage de données dans le contexte d’une stack entièrement écrite en Typescript. Avec tRPC, le code source du client importe directement des éléments provenant du code source du serveur pour déterminer les nommages et le typage des procédures en question.
Quelques éléments de contexte
Les progrès technologiques nous permettent d’écrire des applications toujours plus riches, ce qui s’accompagne d’une complexité toujours plus importante. C’est évidemment le cas des applications web. Les premiers serveurs se contentaient de renvoyer du contenu purement statique, puis des langages de programmation comme PHP, Java ou c# sont arrivés pour rendre le contenu dynamique. De même Javascript est apparu côté client pour apporter des comportements dynamiques dans le navigateur.
Nous avons donc vu se populariser le modèle de stacks logicielles avec un frontend (jQuery, React, Angular, etc) couplé à un backend dans un langage complètement différent. Pour faire communiquer les deux, des standards comme REST ou GraphQL sont couramment utilisés afin de cadrer la communication entre les deux.
Typescript est un langage qui ajoute à Javascript la possibilité de typer les données, de définir des interfaces et des classes. Le code Typescript est “transpilé”, c’est à dire transformé d’un code source Typescript en un autre code Javascript exécutable dans un navigateur. Nous pouvons donc développer un frontend dynamique en Typescript et nous allons pouvoir mettre en place des mécanismes pour désérialiser les données provenant du backend dans des objets typés. Nous pouvons même enrichir la communication entre serveur et client pour véhiculer des métadonnées de typage pour faciliter cette opération.
Ajoutons à ce cocktail NodeJS qui est une technologie qui permet de coder des applications en Javascript côté serveur. Par extension, nous pouvons coder le serveur en Typescript, transpiler et exécuter le Javascript généré avec NodeJS.
Si vous avez bien suivi, nous pouvons autant coder le frontend que le backend de notre stack dans le même langage : en Typescript ! C’est là que tRPC entre en jeu. Plutôt que de mettre en place une API REST par exemple, nous allons tirer partie du fait que nous utilisons le même langage des deux côtés. tRPC met à disposition des classes permettant de décrire les points d’entrée d’une API et de les consommer côté client.
Configuration du projet
Afin de tirer pleinement partie de ce système, cela présuppose une chose : il vaut mieux être dans un dépôt de code unique incluant le client et le serveur. Nous avons donc créé pour l’exemple une application avec deux espaces de travail, un pour le client, un framework Javascript, et un pour le serveur en NodeJS dont voici l’arborescence en figure 1.
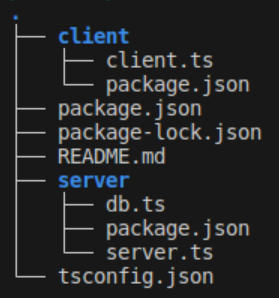
Figure 1 : arborescence
Nous ne détaillerons pas l’implémentation de db.ts. qui n’est pas une vraie base de données mais une simple gestion d’un tableau d’éléments en mémoire pour simplifier les choses pour notre exemple. Nous pourrions aussi bien accéder à une vraie base de données. Les initialisations sont très concises côté serveur (figure 2) :
• Nous instancions un objet tRPC.
• Nous créons un routeur que nous alimenterons avec tous les points d’entrée de l’API. Pour l’exemple nous avons écrit une “query”, c’est à dire une procédure récupérant de la donnée en lecture seule.
• Nous exportons le type de ce routeur à destination du client.
• Nous encapsulons ce routeur dans un serveur HTTP pour le rendre accessible par ce biais de communication. Nous remarquons à travers cet adaptateur HTTP que nous avons un design pattern pour découpler le routeur tRPC du moyen de communication via lequel il est accessible. Il existe d’autres implémentations d’adaptateurs pour interfacer notre routeur dans du code AWS Lambda ou dans le framework Next.JS par exemple.
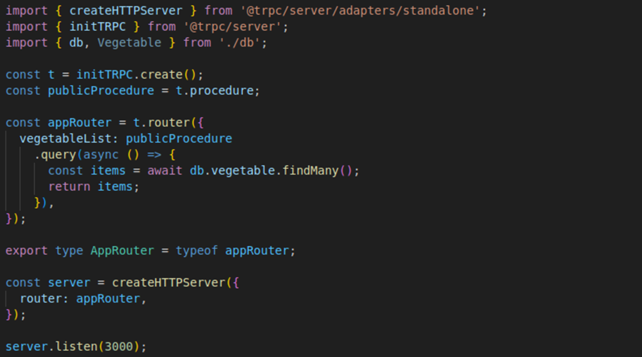
Figure 2 : implémentation serveur
C’est aussi simple côté client (figure 3) :
• Nous importons le type du routeur du serveur.
• Nous l’encapsulons dans un client HTTP puisqu’il est exposé par ce biais par le serveur.
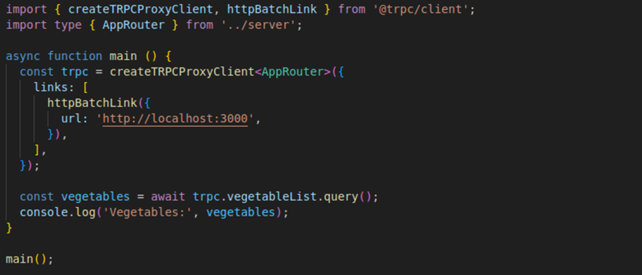
Figure 3 : implémentation client
Il est important de comprendre un élément essentiel évoqué plus haut : nous n’avons pas à lancer explicitement un traitement de génération d’interface avec un outil spécifique à tRPC côté serveur pour exposer les informations au client. Le code source du serveur exporte le type de notre routeur et le code source du client l’importe directement. Si nous modifions l’API serveur, cela va prendre effet directement dans le code client. Avec un éditeur moderne comme VSCode ou Neovim, pas besoin de lancer la compilation manuellement, l´analyse du code et l’auto complétion se feront automatiquement dans l´IDE ! Les éventuelles erreurs de typage ou de nommage vont apparaître soulignées en rouge dans l’éditeur de code. Cela permet de gagner du temps à l’écriture du code et de se rendre compte d’éventuelles incohérences client / serveur pendant la phase d’implémentation.
Et si nous n’utilisions pas un IDE faisant l’analyse du code automatiquement, nous devrions lancer une compilation pour voir s’il n’a pas fait d’erreurs. Cependant, pas besoin de recompiler notre serveur NodeJs pendant que nous développons le client : nous allons juste recompiler le client qui partage le code source du serveur.
Par ailleurs, et ce n’est pas spécifiquement lié à tRPC, l’implémentation des opérations de CI/CD (intégration continue et déploiement continu) sera facilitée par le fait d’être dans un dépôt unique car nous n’avons pas de risques de désynchronisation entre un dépôt client et un dépôt serveur.
Implémentation API serveur et consommation côté client
Nous avons vu dans la mise en place du code l’implémentation d’une query. Nous allons ajouter une mutation à notre routeur, c’est à dire une route qui va modifier des données côté serveur. En l’occurrence ce sera un ajout d’élément dans notre liste de données.

Figure 4 : implémentation mutation serveur
Nous définissons un paramètre en entrée de type string. Côté client, l’analyse du code de l’éditeur de code va faire deux choses comme nous le voyons sur la figure 5 :
• mutate est souligné en rouge car la méthode attend un paramètre qui est manquant.
• L’auto-complétion montre la signature de cette méthode mutate qui attend donc un paramètre “name” et type “string”, un paramètre optionnel et renvoie une promesse encapsulant le résultat.

Figure 5 : appel mutation côté client
Évidement si nous passons en paramètre un entier nous aurons l’erreur :
Argument of type ‘number’ is not assignable to parameter of type ‘string’
Il faut insister sur le fait que nous n’avons pas explicitement lancé d’opération de compilation ou un quelconque traitement spécifique. C’est l’IDE qui a analysé le code. Si nous avions un éditeur basique, nous aurions juste eu à lancer une commande “npm build” à la racine de notre projet pour compiler le client de temps en temps pour vérifier que tout va bien.
Au final, nous pouvons tester le code en ajoutant quelques éléments puis en les listant (figure 6) :

Figure 6 : appel mutations côté client
En lançant le serveur NodeJS, nous obtenons le résultat suivant en exécutant le client (figure 7) :

Figure 7 : résultat d’exécution du client
Validation des données
Dans la figure 4, le paramètre d’entrée est vérifié de manière basique via un typeof. Cela va devenir un peu laborieux si nous devons vérifier des objets complexes. Côté serveur, le routeur de tRPC peut s’interfacer avec des bibliothèques de validation de données comme Zod ou Yup afin de faciliter le travail de vérification d’entrées et de sorties de l’API. Dans l’exemple figure 8, nous décrivons un objet avec trois attributs pour valider le paramètre en entrée de notre route.
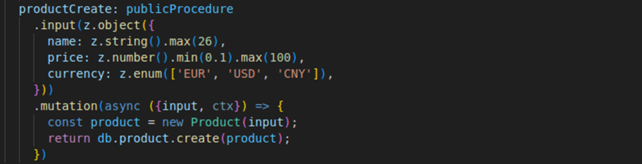
Figure 8 : validation de données côté serveur
Jusqu’ici, il n’y a rien de novateur par rapport à d’autre technologies. Cependant, comme nous sommes sur une stack entièrement en Typescript, et pourvu que nous utilisions des composants bien modulaires, alors nous pourrons réutiliser ce code de validation Zod dans un moteur de formulaire côté frontend par exemple. En effet, nous devons toujours être rigoureux et valider les données à tous les étages, autant à la saisie utilisateur côté client qu’à la réception côté serveur. Le fait d’implémenter le code de validation à un seul endroit permet d’être rigoureux tout en factorisant au maximum pour éviter toute forme de redondance.
Middlewares
Côté serveur, nous pouvons ajouter des comportements lors de l’appel de tout ou partie des routes. Nous pouvons par exemple avoir un middleware pour gérer les routes protégées par une authentification ou encore loguer les appels à l’API.
Côté implémentation, toutes nos routes sont liées à un objet publicProcedure qui découle de t.procedure comme vu sur la figure 2. Nous pouvons aisément créer d’autre objets procédure auquel nous pouvons positionner un middleware.
Inconvénients
Par définition, même si elle résout l’interfaçage client / serveur de manière élégante, cette brique logicielle ne fonctionnera qu’avec une stack entièrement en Typescript ce qui est très restrictif.
D’autre part, des briques logicielles comme Swagger ou API Platform vont générer des pages webs qui vont lister tous les points d’entrée de l’API et même permettre d’interagir avec elle. C’est souvent pratique pour déboguer une API ou pour la documenter. tRPC est très modulaire, et donc pas forcément couplé à un serveur web. Donc cette fonctionnalité n’est pas présente de base. Si nous en avons besoin, il faudra trouver une implémentation réalisée par la communauté ou bien s’y atteler nous-mêmes.
Avantages
tRPC est agnostique en terme de framework. Dès lors que nous sommes en Typescript nous pouvons l’intégrer sur un frontend avec Angular ou React par exemple. Elle est même souvent mise en avant avec NextJS qui est un framework assez complet qui intègre du React côté front et du rendu côté serveur avec Node. C’est assez avantageux, dans un contexte où la guerre des frameworks fait rage, de ne pas être pieds et poings liés à l’un d’entre eux. L’avantage évident en termes de développement est la prise d’effet immédiate de toute modification de l’API et la diminution du risque d’un oubli de synchronisation client / serveur. La forte modularité et l’unicité du langage permettent de factoriser le code de validation de données côté client et serveur.
Conclusion
tRPC n’est donc pas la solution à tous les problèmes. Mais si votre stack est en mono dépôt et entièrement en Typescript, l’utilisation de tRPC résoudra élégamment vos problèmes d’interfaçage entre client et serveur en vous abstrayant des détails techniques de communication entre les deux et s’adaptera à n’importe quel framework.
Il est possible de retrouver l’intégralité de cet article dans le numéro 261 du mois de février 2024 du magazine « Programmez ».