Dans le domaine des outils de test de montée en charge permettant d’étudier les performances d’applications web, il existe globalement plusieurs catégories : des outils commerciaux pour la majorité très onéreux, des outils gratuits basiques ou austères ou encore des outils gratuits devenus obsolètes avec le temps.
Voici une nouvelle solution, Gatling, un outil de test de montée en charge gratuit et open source s’appuyant sur un ensemble de technologies dont une des facultés est d’allier simplicité et fiabilité.
Nous allons dans cet article présenter l’outil sous la forme d’un didacticiel permettant de vous aider à le découvrir mais aussi le prendre en main.
Présentation de l’outil
L’outil tire son nom de la mitrailleuse créée par l’américain Richard Gatling qui fut une arme fiable, puissante et facile à alimenter.
Afin de parvenir à égaler les qualités de son patronyme, cette solution se différencie des autres outils de test de charge en évitant d’utiliser un thread pour simuler un utilisateur virtuel. Gatling s’appuie pour cela sur le modèle d’acteurs d’Akka consistant à communiquer par échange de messages asynchrones. Cette architecture permet de simuler un nombre d’utilisateurs plus important à partir d’une seule machine.
L’utilisation d’Akka a poussé le choix du langage Scala pour le développement de l’outil mais également pour le langage des scripts de test. Ces derniers reposent plutôt en réalité sur un langage dédié en Scala que l’on appelle également DSL (domaine specific language). Un ensemble d’API que nous présenterons par la suite permet de simuler les opérations réalisées par un utilisateur naviguant dans l’application web à tester en émettant notamment des requêtes HTTP.
Pour mettre en œuvre ces requêtes de manière optimale, Gatling s’appuie sur la librairie Asynchronous HTTP Client et sur le framework Netty qui sont également sous licence Apache 2.0.
Enfin, pour permettre l’affichage de rapports de tests, l’outil génère un ensemble de pages HTML reposant sur les librairies javascript highstock et highcharts afin de produire des graphiques de manière optimisée.
Maintenant que vous connaissez l’architecture technique et les différentes briques qui composent l’outil, passons aux explications pour l’installation.
Installation de l’outil
Il existe principalement deux possibilités pour utiliser Gatling en tant qu’outil de test de montée en charge :
- Télécharger l’outil et dézipper l’archive dans un répertoire mettant à disposition deux scripts (bat ou shell selon votre OS) permettant de lancer l’outil d’enregistrement d’un scénario puis de démarrer le moteur d’exécution d’un test
- Intégrer la solution au sein de l’outil de développement Eclipse afin de disposer d’un projet « Gatling » permettant de manière plus confortable d’enregistrer, éditer (en bénéficiant notamment de la complétion) et exécuter les scripts de test
La première solution permet de déployer une solution de tir en quelques minutes alors que la seconde met à disposition un environnement de développement parfois nécessaire pour réaliser des scénarios de tests complexes.
Nous allons détailler l’utilisation au sein d’Eclipse qui nous paraît être la meilleure façon d’utiliser pleinement l’outil. Dans tous les cas, il vous faut disposer d’un JDK 6 minimum sachant qu’il est préconisé d’utiliser la version 7.
Il faut commencer par procéder à l’installation de l’outil de développement Eclipse dont la version supportée est Juno.
L’ajout de plusieurs plug-in (figure 1 et 2) est nécessaire. Voici les liens à ajouter :
- Plug-in Scala IDE pour Eclipse : http://download.scala-ide.org/sdk/e38/scala210/stable/site
- Plug-in Maven Scala pour Eclipse : http://alchim31.free.fr/m2e-scala/update-site
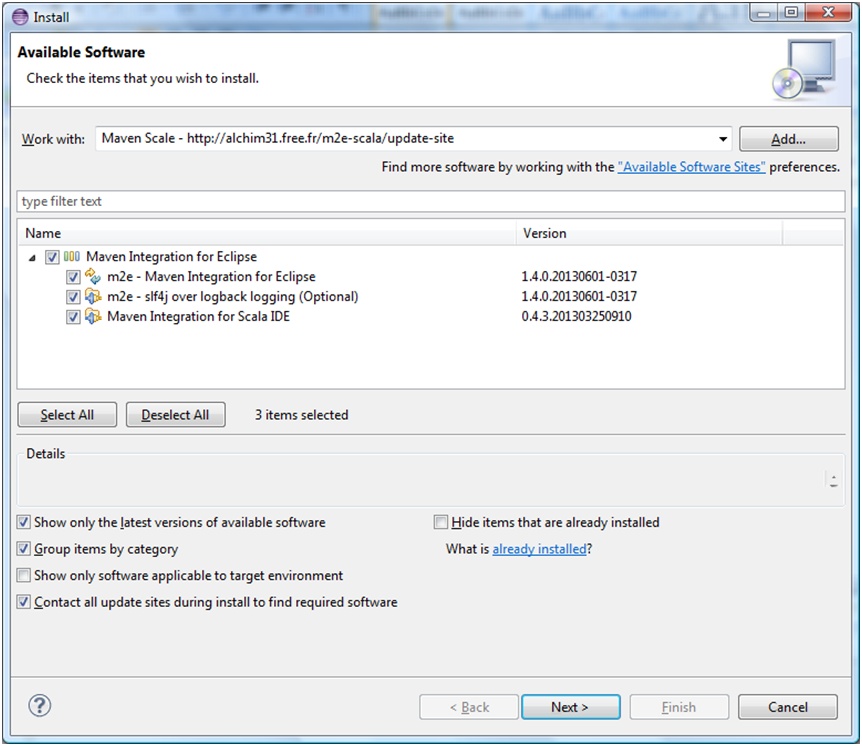
Figure 1
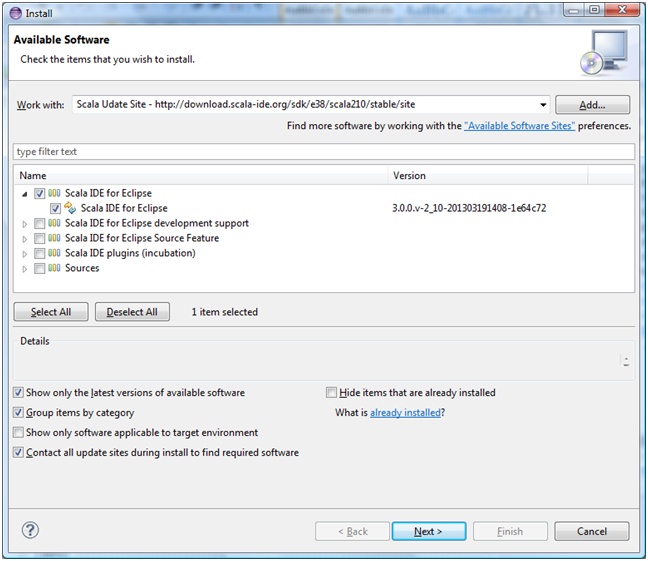
Figure 2
Par la suite (figure 3), il faut configurer le catalogue archetype Maven suivant : http://repository.excilys.com/content/groups/public/archetype-catalog.xml
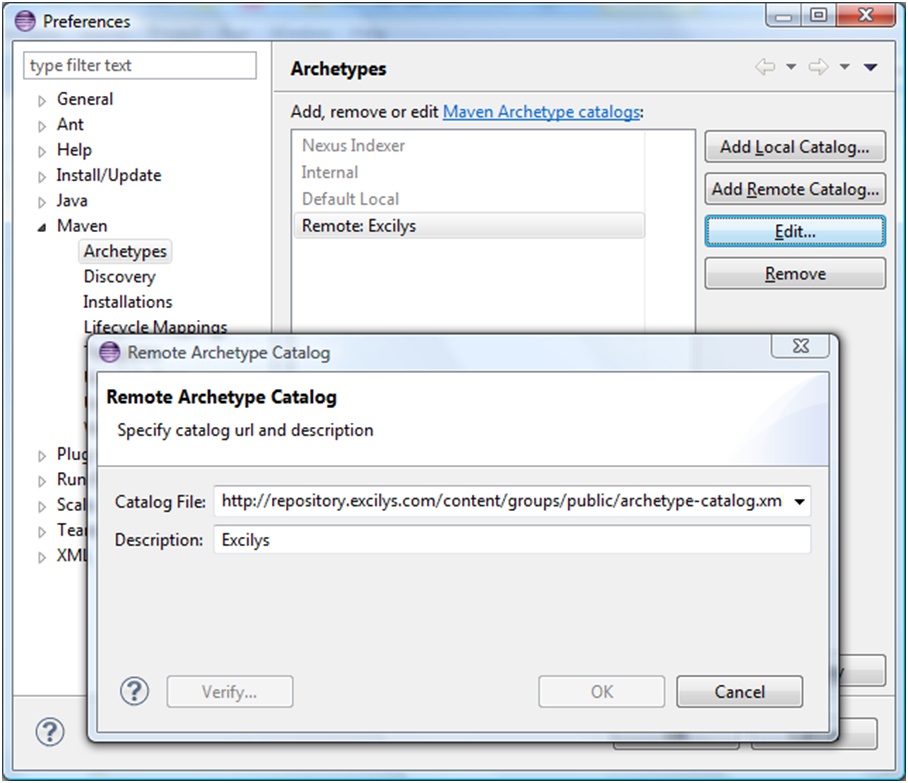
Figure 3
Voilà, vous pouvez maintenant créer un nouveau projet Maven en choisissant l’archetype Gatling qui vous propose à ce jour deux versions de l’application : 1.5.2 et 2.0.0. Dans notre cas, nous allons travailler avec la version actuellement la plus récente. Il faut ensuite renseigner un groupId et un artifactId pour votre projet (figure 4 et 5)
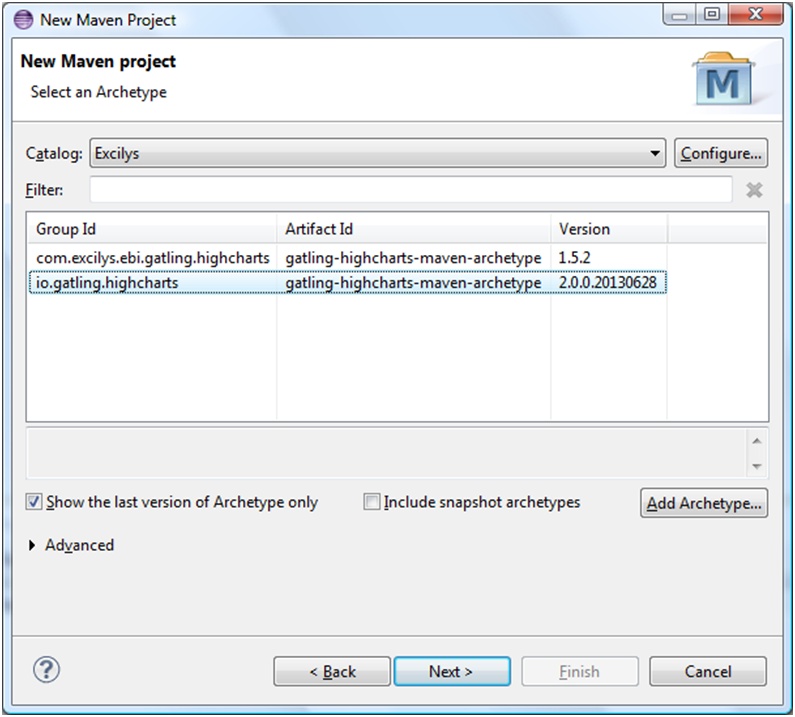
Figure 4
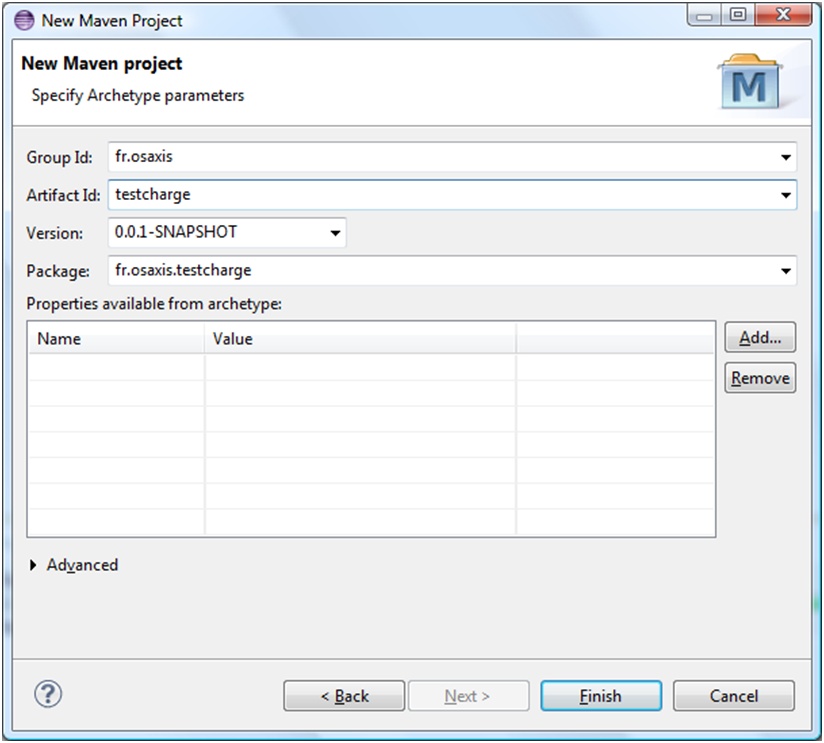
Figure 5
Votre projet est automatiquement créé dont voici l’arborescence et les différents fichiers qui le composent (figure 6).
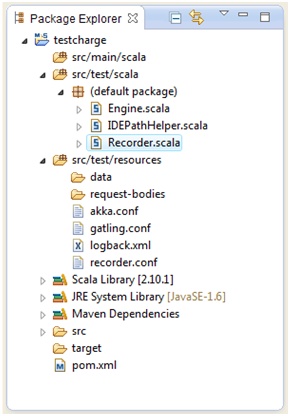
Figure 6
Ce projet comprend notamment :
- Recorder.scala : programme Scala permettant de lancer l’outil enregisteur appelé également « recorder » en anglais
- Engine.scala : programme Scala représentant le moteur permettant d’exécuter un script de test
- Le répertoire « data » permettant de stocker des fichiers à charger pour simuler des jeux de données
- Plusieurs fichiers de configuration pour l’outil d’enregistrement, le moteur, etc.
- Un fichier logback.xml permettant d’être plus ou moins verbeux pour chaque requête HTTP émise. Il est cependant conseillé d’éviter de mettre le niveau de trace le plus détaillé lors de l’exécution des tests de montée en charge pour ne pas biaiser les résultats.
Si vous souhaitez changer de version suite à la mise à disposition d’une nouvelle fonctionnalité qui vous intéresse ou d’une correction de bug, il vous suffit d’éditer le fichier pom.xml et de renseigner la version de ces librairies :
|
1 2 |
2.0.0-M3a 2.0.0-M3a |
Pour connaître les différentes versions, vous pouvez vous rendre sur le github du projet et voir les versions des différents tags mis à disposition :
https://github.com/excilys/gatling
Vous l’aurez compris, nous allons vous montrer comment fonctionne la version 2.0.0-M3a de Gatling.
Enregistrement d’un script de test
Pour faciliter la mise en place d’un script de test, l’outil propose un « recorder » permettant d’enregistrer les requêtes HTTP d’un scénario réalisé par l’intermédiaire d’un navigateur.
Pour lancer le recorder à partir d’Eclipse, il suffit de cliquer sur le fichier « Recorder.scala » et exécuter en tant qu’application Scala (figure 7).
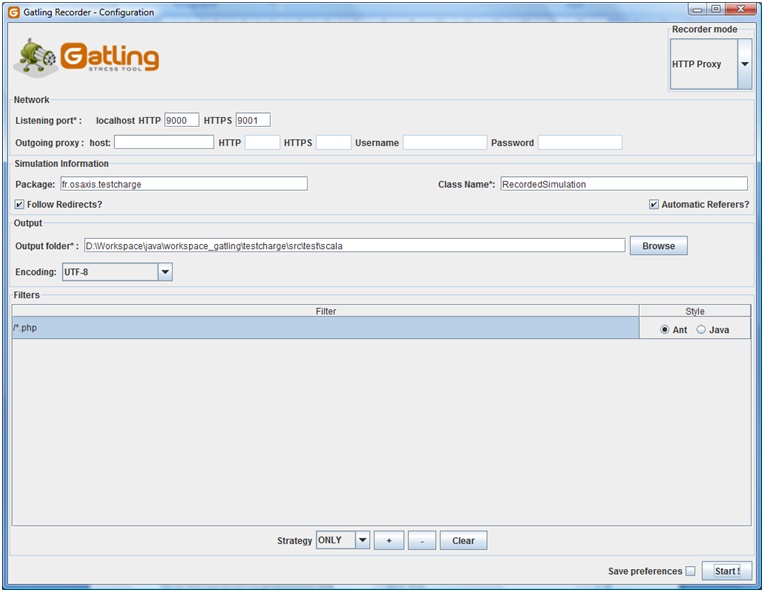
Figure 7
Il existe deux modes d’enregistrement :
- HTTP Proxy : le recorder joue un rôle de proxy par lequel votre navigateur doit pointer afin d’enregistrer l’ensemble des requêtes. Par défaut, le port HTTP est 8000 mais cela est configurable
- HAR Converter : il est envisageable d’enregistrer votre scénario avec votre navigateur préféré et de générer un fichier au format HAR (HTTP Archive) représentant l’ensemble des requêtes (il s’agit d’une norme de description au format JSON). Ce fichier peut alors être chargé dans l’outil qui le transforme en script
Dans les deux cas, il est possible d’indiquer une stratégie d’enregistrement en créant des filtres permettant de spécifier les ressources à exclure (comme par exemple les éléments statiques css, js, etc.) ou bien les ressources uniquement à enregistrer (comme par exemple /**/*.php) selon les besoins des tests.
Lors de l’enregistrement en mode HTTP proxy, il est possible de saisir un tag entre chaque page afin de voir apparaître des commentaires dans le script généré. Par ailleurs, l’outil présente les informations sur les requêtes et les réponses (figure 8).
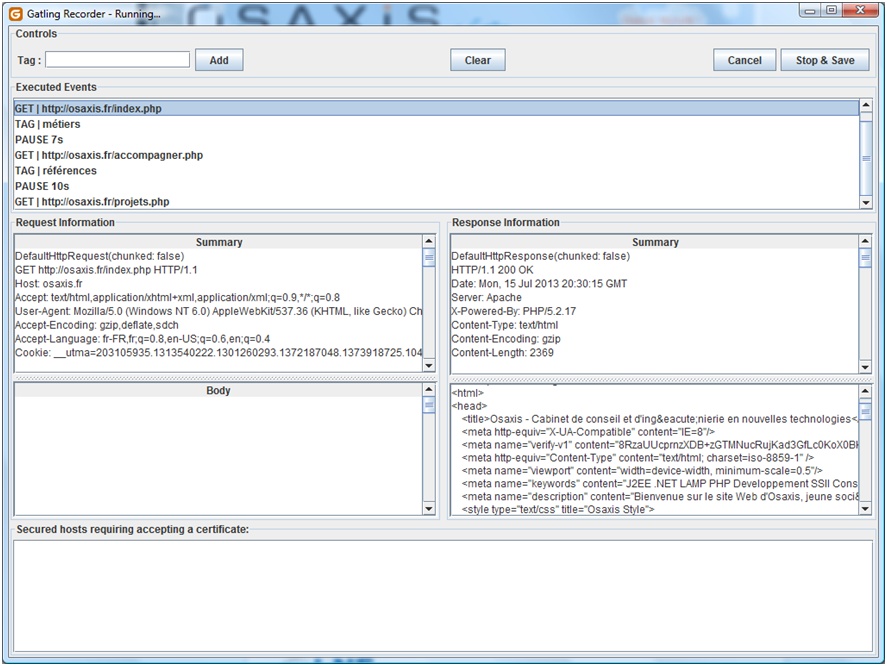
Figure 8
Un script très propre et facilement compréhensible est automatiquement généré intégrant notamment les temps de pause réels pris entre chaque clic lors de l’enregistrement :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
class RecordedSimulation extends Simulation { val httpProtocol = http .baseURL("http://osaxis.fr") .acceptHeader("text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8") .acceptEncodingHeader("gzip,deflate,sdch") .acceptLanguageHeader("fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4") .userAgentHeader("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.72 Safari/537.36") val scn = scenario("Scenario Name") //accueil .exec(http("request_1") .get("""/index.php""")) //métiers .pause(7) .exec(http("request_2") .get("""/accompagner.php""")) //références .pause(10) .exec(http("request_3") .get("""/projets.php""")) setUp(scn.inject(atOnce(1 user))).protocols(httpProtocol) } |
Personnalisation du script de test
A partir du fichier généré, on peut faire évoluer le script afin de le rendre plus dynamique en injectant des jeux de données variables. Il est également possible de modifier le script en analysant les réponses des requêtes afin d’y extraire des informations nécessaires pour poursuivre correctement le scénario.
Le langage DSL proposé pour ces scripts dispose de nombreuses API segmentées selon sept grandes catégories que nous vous présentons à travers quelques exemples. A noter que nous présentons les principales API mais elles ne sont pas toutes décrites ici.
Scenario definition
Cette première catégorie permet de déclarer un ou même plusieurs scénarios dans un script à partir de l’API « scenario » afin de reproduire le comportement d’utilisateurs. L’autre API importante est « exec » permettant de réaliser des traitements comme par exemple l’exécution d’une requête HTTP :
|
1 2 |
val scn = scenario("Scenario1").exec(http("request_1").get("""/index.php""")) val scn2 = scenario("Scenario2").exec(http("request_2").get("""/index2.php""")) |
Une notion de « Group » offre la possibilité de regrouper plusieurs requêtes afin d’avoir des statistiques pour un ensemble d’enchaînements, sachant que l’on peut imbriquer plusieurs groupes.
De nombreuses autres API telles que « repeat » et « during » permettent d’itérer une partie d’un scénario, alors que l’insertion des temporisations au sein du scénario se fait à l’aide de « pause » et « pauseExp ».
Enfin, il est possible de réaliser des conditions « doIf » et « doIfOrElse » en s’appuyant sur des attributs en session accessibles à partir d’EL (expression language).
HTTP Action
Comme vous avez pu le constater dans l’exemple de code précédent, une requête HTTP de type GET a été réalisée mais il est bien évidemment possible de simuler d’autres types de requêtes HTTP comme « POST », « PUT », « DELETE », etc. et également de passer des paramètres à ces requêtes.
Voici par exemple une requête en POST pour l’authentification à un site en HTTP :
|
1 2 3 4 5 |
val scn = scenario("SimpleLogin") .exec(http("login") .post("""/login.php""") .param("""login""", """john""") .param("""password""", """azerty""")) |
Une API est disponible pour gérer les authentifications basiques :
|
1 2 3 4 |
val scn = scenario("BasicLogin") .exec(http("login") .get("""/login.php""") .basicAuth("""john""", """azerty""")) |
HTTP Configuration
Ce bloc de code est présent au début du script généré suite à l’enregistrement avec le recorder :
|
1 2 3 4 5 6 |
val httpProtocol = http .baseURL("http://osaxis.fr") .acceptHeader("text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8") .acceptEncodingHeader("gzip,deflate,sdch") .acceptLanguageHeader("fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4") .userAgentHeader("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.72 Safari/537.36") |
Ceci permet de configurer seulement une fois un certain nombre d’informations pour l’ensemble des requêtes HTTP qui seront injectées par la suite dans le script.
Il est possible par exemple de spécifier l’URL de base du site à tester sachant qu’il est même proposé de renseigner plusieurs « baseURLs » lorsque votre site est en cluster et que vous souhaitez injecter une charge sur chacun des serveurs sans passer par le répartiteur de charge. Il est également envisageable de configurer un proxy HTTP si vous êtes contraint de passer par un proxy pour accéder au site à tester.
Feeder definition
Pour pouvoir injecter des jeux de données variables, vous pouvez charger des fichiers de différents formats voire même récupérer des informations en base de données. Plusieurs stratégies offrent la possibilité de manipuler des données afin de les injecter de manière aléatoire ou bien circulaire.
Reprenons notre exemple précédent mais en utilisant désormais le fichier « users.csv » placé dans le répertoire « data » de votre arborescence et dont voici le contenu :
login,password // la première ligne permet d’attribuer un nom à chaque donnée
john,azerty
kevin,soleil
Le code pour le charger et l’injecter dans le scenario est le suivant :
|
1 2 3 4 5 6 7 8 9 10 |
val users = csv("users.csv") // chargement du fichier val scn = scenario("FeedLogin") .feed(users) // injection des données .exec(http("login") .post("""/login.php""") .param("""login""", "${login}") // passage du login .param("""password""", "${password}") // passage du password .check(currentLocation.is(baseURL+"/private.php"))) |
Checks
Comme vous avez pu le constater dans l’exemple précédent, nous avons vérifié que la page obtenue après l’authentification était bien « private.php » en utilisant l’API « check ». Il existe d’autres possibilités comme par exemple vérifier le code retour HTTP qui en principe est de « 200 » si tout va bien.
Il est envisageable de valider le contenu retourné mais également de le parser afin de récupérer des informations contenues dans le flux en utilisant des expressions régulières. Ceci est indispensable dans certains cas de figure où un identifiant est généré dynamiquement dans la page et qu’il faut ensuite le transmettre en paramètre de la requête suivante.
Voici un exemple :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
val scn = scenario("UpdateScore") .feed(users) .exec(http("login") .post("""/login.php""") .param("""login""", "${login}") .param("""password""", "${password}") .check(currentLocation.is(baseURL+"/private.php"))) .exec(http("monde") .get("""/private_monde.php?monde=3""") .check( regex("""<input type="hidden" name="tab" value="([0-9]*)" />""") // expression régulière .saveAs("idtab"))) // sauvegarde d’une variable .exec(http("update") .post("""/updatescore.php""") .headers(headers_xml) .param("""tab""", "${idtab}") // utilisation de la variable .param("""score""", """31000""") .param("""birds""", """2""") .check(status.is(200))) // vérification du status code 200 |
Scenario configuration
Ce bloc de code est présent à la fin du script généré suite à l’enregistrement avec le recorder :
|
1 |
setUp(scn.inject(atOnce(1 user))).protocols(httpProtocol) |
Cette ligne de code permet de configurer le scénario de test à simuler en précisant le nombre d’utilisateurs. Par défaut, c’est simplement un utilisateur virtuel qui est proposé par l’enregistreur mais en général, c’est une montée en charge progressive qui est requise. Celle-ci se fait en précisant notamment des durées de préparation.
Voici une configuration de scénario s’inspirant fortement de l’exemple fourni dans le wiki de l’outil et qui permet d’avoir une idée du spectre des possibilités offertes par la solution :
|
1 2 3 4 5 6 7 8 9 |
setUp(scn.inject(nothingFor(4 seconds), atOnce(10 users), ramp(10 users) over (5 seconds), constantRate(20 usersPerSec) during (15 seconds), rampRate(10 usersPerSec) to(20 usersPerSec) during(10 minutes), split(1000 users).into(ramp(10 users) over (10 seconds)) .separatedBy(10 seconds), split(1000 users).into(ramp(10 users) over (10 seconds)) .separatedBy(atOnce(30 users)))).protocols(httpProtocol) |
Assertions
Afin de valider que le scénario répond à certaines exigences, l’outil permet de spécifier un certain nombre de vérifications sur les temps de réponse ou le nombre de requêtes en échec. Cela peut être au niveau global ou bien sur une requête en particulier.
Voici un exemple permettant de vérifier que le temps global de chaque requête est inférieur à une seconde, qu’il y a plus de 98% de requêtes réussies et que la durée de traitement de la page de login est comprise entre 100 et 500 millisecondes :
|
1 2 3 4 5 |
setUp(scn.inject(atOnce(1 user))).protocols(httpProtocol) .assertions( global.responseTime.max.lessThan(1000), global.successfulRequests.percent.greaterThan(98), details("login").requestsPerSec.greaterThan(100).lessThan(500)) |
Suite à l’exécution du test, un rapport indique pour chaque assertion si elle est vérifiée ou non et indique si la simulation a échoué ou réussi selon vos critères :
Global : max response time is less than 1000 : false
Global percentage of requests OK is greater than 98 : true
login : requests per second is greater than 100 : false
login : requests per second is less than 500 : true
Simulation failed.
Exécution et analyse des résultats
Maintenant que vous avez un script de test permettant de parfaitement simuler le ou les scénarios avec le nombre d’utilisateurs de votre choix, il faut désormais lancer le test (en pratique, le test est exécuté au cours de la création du script pour valider le fonctionnement du scénario surtout lorsqu’il est complexe).
Pour lancer votre test depuis Eclipse, il suffit de cliquer sur le fichier « Engine.scala » et de l’exécuter en tant qu’application Scala. Si votre projet comporte plusieurs scripts de test, la liste apparaît dans la console et vous pouvez choisir la simulation de votre choix. Ensuite, l’outil vous permet de spécifier un identifiant (afin de pouvoir facilement identifier la simulation réalisée parmi l’ensemble des simulations que vous pouvez être amené à produire) et une description (permettant d’avoir un commentaire dans le rapport).
Pendant l’exécution des tests, des données apparaissent toutes les cinq secondes permettant d’avoir un aperçu de l’état du test en cours (figure 9).
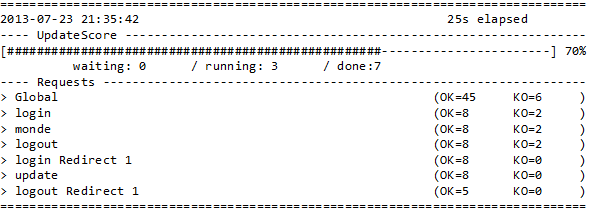
Figure 9
A la fin du test, un rapport textuel simple résume le test qui a été réalisé (figure 10).
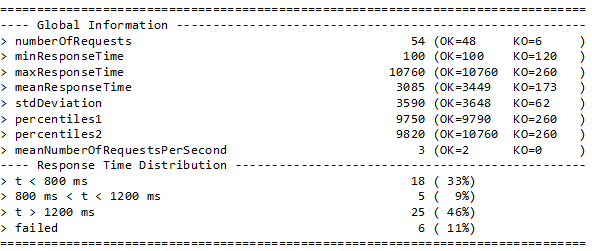
Figure 10
Par ailleurs, un certain nombre de fichiers sont automatiquement générés dans le répertoire « target/results/id-timestamp » de votre projet dans Eclipse (il faut rafraîchir votre projet pour les voir apparaître).
Un fichier « simulation.log » contenant des informations sur chaque requête émise est généré. Il est envisageable d’ajouter des informations personnalisées dans ce fichier en ajoutant à la configuration HTTP l’API « extraInfoExtractor » permettant de récupérer des données dans la « session », la « request », la « response » ou bien le « status » :
|
1 2 3 4 5 6 7 |
val httpProtocol = http .baseURL("https://www.osaxis.fr") .acceptHeader("*/*") .acceptEncodingHeader("gzip,deflate,sdch") .acceptLanguageHeader("fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4") .extraInfoExtractor((status:Status, session:Session, request:Request, response: Response) => { List[String](request.getRawUrl(), response.getStatusCode.toString())}) |
Un fichier « stats.tsv » comporte un ensemble de statistiques sur la simulation réalisée comme par exemple le nombre de requêtes, le nombre de requêtes en erreur, le temps de réponse minimum, le temps de réponse maximum, etc.
Un rapport complet au format HTML est également généré contenant un grand nombre de tableaux et de graphiques agréables à l’œil et surtout représentant une mine d’informations sur la simulation réalisée (figure 11).
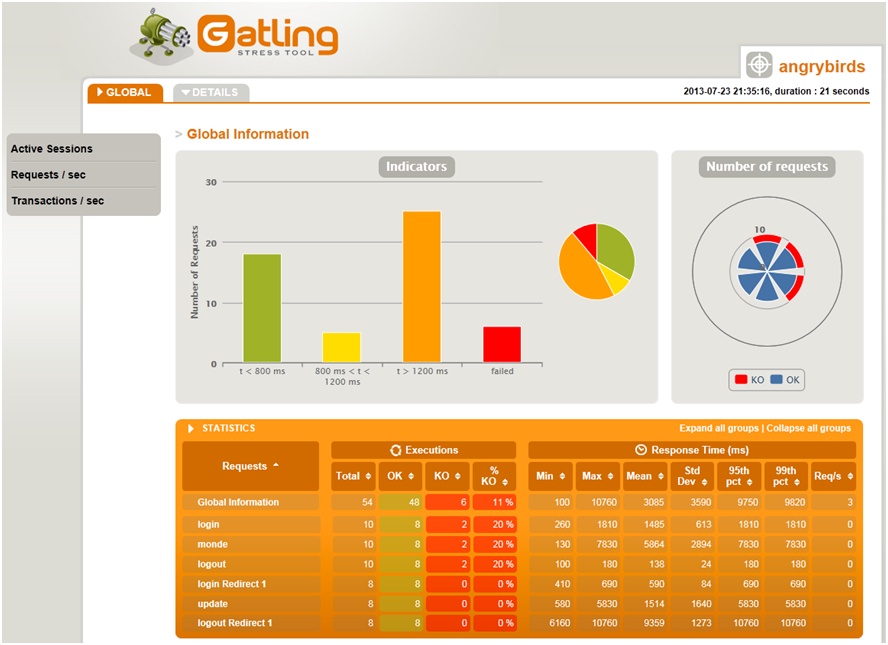
Figure 11
Conclusion
Gatling dispose des fonctionnalités nécessaires pour mener à bien une campagne de tests de montée en charge. On ressent que cet outil a été conçu par des développeurs qui connaissent bien les besoins, et pour des développeurs qui veulent une solution simple, flexible et agréable.
Les puristes diront qu’il manque une interface pour faciliter l’exécution et la configuration de la simulation.
On peut regretter l’absence d’une solution pour coordonner une simulation depuis plusieurs injecteurs (dans le cas où une très grosse charge est à réaliser) mais cela reste malgré tout envisageable en réalisant quelques opérations manuelles indiquées sur le wiki de l’outil.
Ceci dit, pour une solution gratuite et encore jeune (à peine deux ans), l’outil se révèle déjà complet et bien documenté. Par ailleurs, une véritable communauté semble s’être créée et le support apparaît réactif.
Sachez que nous avons essentiellement présenté l’outil comme étant une solution de test de montée en charge mais il est tout à fait envisageable d’utiliser les scripts pour réaliser des tests fonctionnels de non régression. En effet, il existe également un plug-in Jenkins permettant de disposer d’un rapport de tests pour chaque construction au sein de votre usine logicielle.
Liens et références
Site de l’outil : http://gatling-tool.org
Documentation de l’outil : https://github.com/excilys/gatling/wiki
Google User Group de l’outil : https://groups.google.com/forum/#!forum/gatling
Modèle d’acteurs Akka : http://akka.io
Langage Scala : http://www.scala-lang.org
Netty : http://netty.io
Async HTTP Client : https://github.com/AsyncHttpClient/async-http-client
Librairies javascript highstock et highcharts : http://www.highcharts.com/products/highcharts et http://www.highcharts.com/products/highstock
Licence Apache 2.0 : http://www.tldrlegal.com/license/apache-license-2.0-(apache-2.0)
Eclipse Juno : http://www.eclipse.org/downloads/download.php?file=/eclipse/downloads/drops4/R-4.2.2-201302041200/eclipse-SDK-4.2.2-win32.zip
Il est possible de retrouver l’intégralité de cet article dans le numéro 168 du mois de Novembre 2013 du magazine « Programmez ».